本文我们将探讨 MySQL 索引的重要概念以及实现原理。
索引
常见索引模型
| 模型 | 优点 | 缺点 |
|---|---|---|
| 哈希表 | 等值查询和范围查询都非常高效 | 插入数据成本高,只适合静态数据存储引擎 |
| 二叉搜索树 | 查询和插入都很高效 | 树高过大,实际生产中要多次读取磁盘,查询效率不高 |
| N叉树 | 查询和插入都高效、且树高较低 | – |
InnoDB索引模型
InnoDB使用B+树索引模型,每一个索引都是一棵独立的B+树;
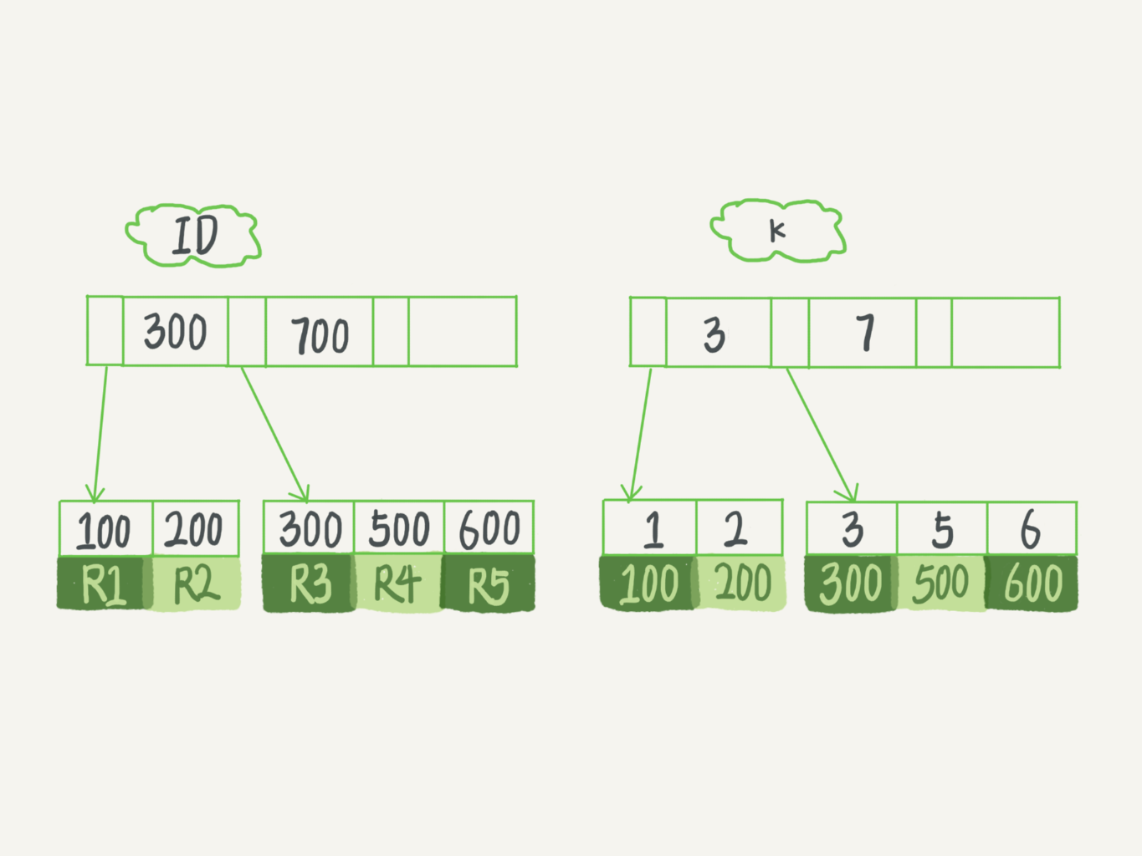
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。注意B+树的节点都对应着InnoDB的一个数据页,默认大小16K。也就是说叶子节点里包含着多行数据;
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
页分裂:插入新数据的时候,B+树节点所在的数据页满了之后,节点会发生分裂,需要申请新的数据页来保存新节点,这个过程叫做页分裂。 –> 页分裂会使得空间利用率下降,并降低性能。
页大小:InnoDB页大小(innodb_page_size)默认值为16kb,可以通过调整页大小来间接改变B+树分叉数量
自增主键:考虑到页分裂的性能影响,使用自增主键要比其他业务字段作为主键ID要更优。因为自增主键的每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
不必使用自增主键的场景:如果该表只有一个索引,且该索引为唯一索引,则适合让该索引直接作为主键索引。这样子可以避免生成两棵索引树以节省空间,并且避免回表以增加查询性能。
回表 :使用非主键索引查询数据的时候,如果所查数据包含了主键以外的数据,则需要回到主键索引进行二次查询,这个过程称为回表。 –> 因此应该尽量使用主键索引查询。
覆盖索引:当二级索引已经“覆盖”了查询需求的时候,该索引可称为覆盖索引。使用覆盖索引可以回表操作,减少搜索B+树的次数。因此,可以为高频查询建立覆盖索引。
最左前缀原则:只要查询条件能够满足联合索引的最左前缀,则可以使用该联合索引来加速检索。因此,建立联合索引时候,需要合理安排字段顺序,充分利用最左前缀原则来减少索引数量。
**索引下推优化(index condition pushdown)**:MySQL5.6之后引入了索引下推,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
Change Buffer:当对二级索引数据页进行变更,而这些数据页又不在buffer pool中的时候,会使用Change Buffer来缓存这些变更。这些INSERT, UPDATE, 或者 DELETE 操作(DML)带来的变更会在这些数据页被其他读操作加载进缓存的时候被合并。简单来讲,Change Buffer是用来”懒合并”,将非必需的磁盘读写延后。因此适合写多读少的业务情景。另外,唯一索引无法使用ChangeBuffer,因此一般推荐优先使用普通索引。
MySQL误判索引解决办法
- 对于由于索引统计信息不准确导致的问题,你可以用 analyze table 来解决;例如,使用delete来删除数据,会导致统计信息不准。
- 对于其他优化器误判的情况,你可以在应用端用 force index 来强行指定索引,也可以通过修改语句来引导优化器,还可以通过增加或者删除索引来绕过这个问题。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 duval1024@gmail.com

