整体架构
掌握了ES的基本用法后,我们来深入了解一下ES的整体架构。
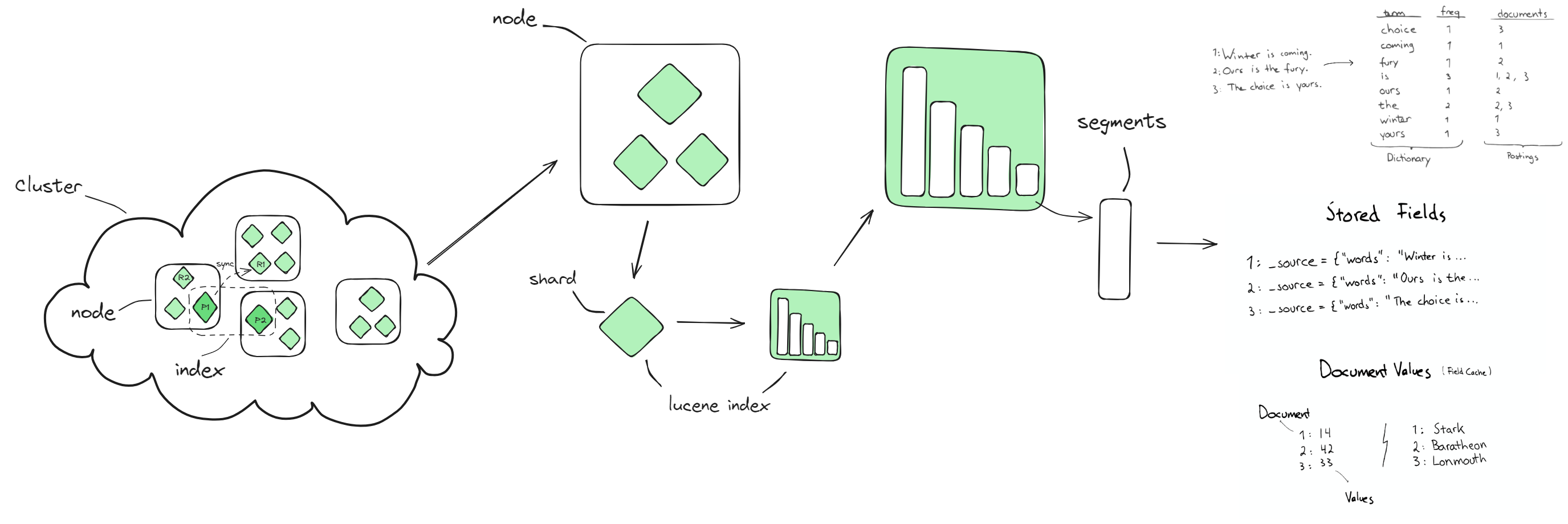
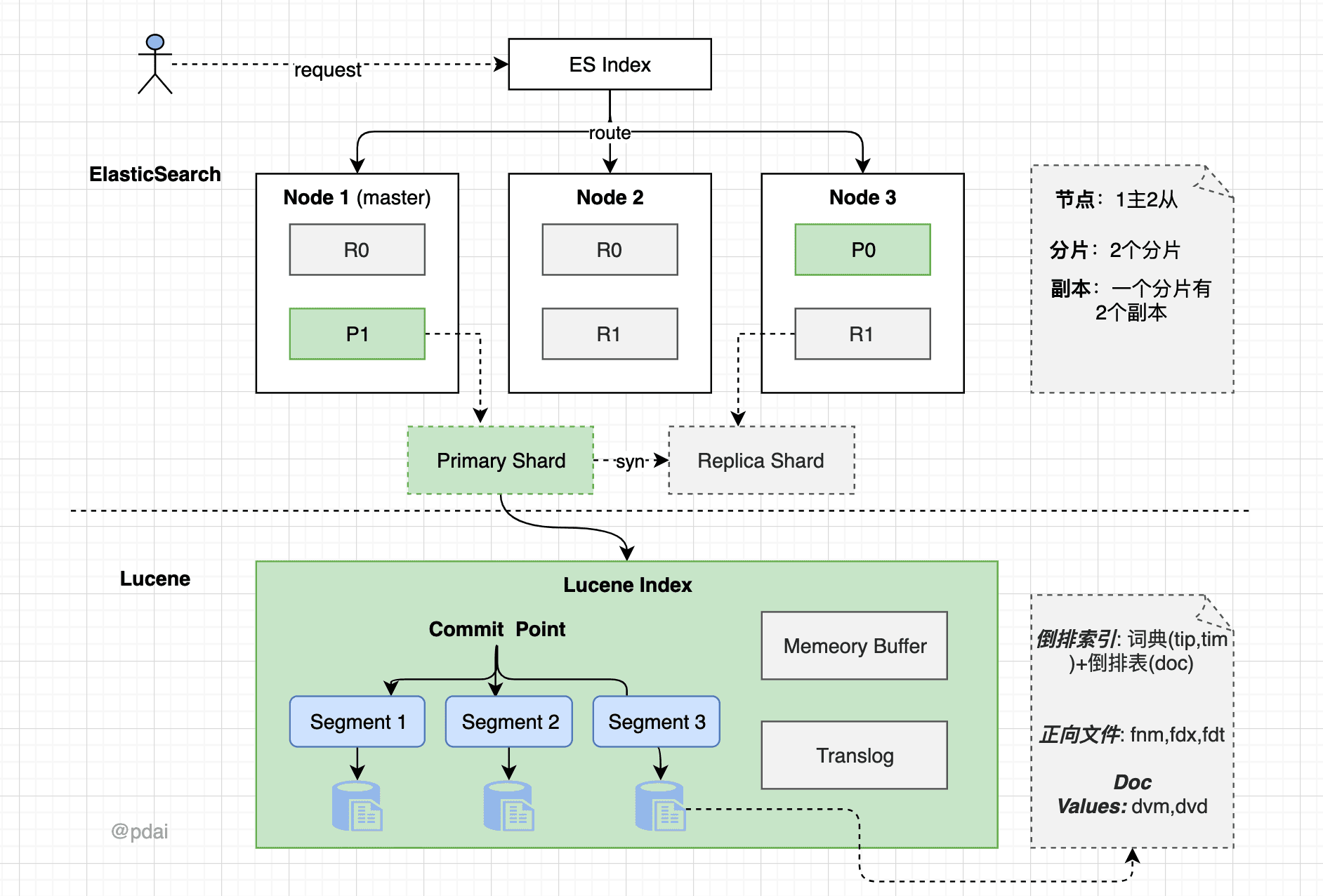
ES集群模式下,有多个节点(node)组成一个完整集群。每个节点可以承担不同的角色从而构成不同的节点,包括但不限于:
- 主节点(Master Node)
- 负责集群的管理和协调工作,比如创建或删除索引、跟踪集群中节点的状态、分配碎片(shards)等;
- 主节点并不直接参与文档的索引或搜索操作,以减轻其负担;
- 通常建议设置较少数量的专用主节点,以确保集群的稳定性;
- 数据节点(Data Node):
- 存储数据片段(shards)并参与文档的索引和搜索操作。
- 数据节点是集群中最耗费资源的部分,因为它们需要处理数据的存储和检索。
- 根据集群规模和硬件配置,可以有多台数据节点。
- 协调节点(Coordinating Node)
- 虽然不是一个官方的节点角色,但在实践中,可以配置节点不承担数据存储或主节点职责,专门负责接收客户端请求、协调搜索和索引操作。
- 这有助于分散主节点和数据节点的压力,提高集群的整体响应速度。
- 专用主节点(Dedicated Master-Eligible Node):
- 仅具有主节点资格,不承担数据存储任务,专注于集群管理。
- 用于避免主节点因其他任务过载。
- 冻结节点(Frozen Node):
- 专门用于存储冻结索引,这些索引的数据访问频率较低,但需要长期保存。
- 主节点(Master Node)
数据节点(Data Node负责持有数据分片(包括主分片和副本分片),参与文档的索引、搜索、更新以及删除等数据处理操作。当索引数据时,Elasticsearch 会根据配置的分片策略将数据分布在网络中的各个数据节点上,实现数据的水平扩展和负载均衡。此外,数据节点还负责维护分片的状态,确保数据的完整性和高可用性;
每一个Index由多个分片构成,这些分片会分散在不同数据节点上;
每一个分片是一个最小级别的工作单元,本质上是一个功能完备且独立的Luncene 索引实例。每个ES索引可以被分成多个分片,每个分片都包含索引中部分数据的文档集合。分片有两种类型:主分片(Primary Shards) 和 副本分片(Replica Shards)。主分片是索引数据存储的基本单位,而副本分片则是主分片的拷贝,用于提高数据的可用性和读取性能;
段(Segments)在分片内部,数据被组织成多个段。每个段都是一个不可变的倒排索引结构,包含了文档的一部分。随着时间推移,新的文档被写入新的段中,旧的段可能被合并以优化查询性能和磁盘使用。
索引流程
Elasticsearch(ES)文档插入到索引的过程大致遵循以下步骤:
- 客户端请求:首先,客户端(比如一个应用程序或者API请求)向Elasticsearch集群发送一个HTTP PUT或POST请求,请求中包含要插入文档的具体信息,比如文档的JSON内容、目标索引名称以及可选的ID。
- 节点接收:请求被发送到集群中的任何节点,这个节点被称为协调节点。协调节点负责接收请求并进行后续的路由操作,而不直接处理数据的存储或检索。
- 路由决策**:协调节点根据文档ID和索引的配置计算出该文档应存储在哪个主分片上。这个过程基于一种散列算法,确保相同ID的文档总是被路由到同一个分片上。
转发请求:协调节点将请求转发给存储目标主分片的数据节点。如果请求中包含写操作(如索引或更新),则直接转发到该主分片所在节点。 - 文档处理:
- 分析:数据节点接收到请求后,首先对文档内容进行分析,这包括分词(tokenization)、去除停用词、转换为小写等,以便创建适合搜索的结构。
- 索引文档:经过分析后,文档被序列化为Lucene的内部格式,并添加到相应的主分片中。这个过程涉及到倒排索引的构建或更新,确保文档可以被快速检索。
- 事务日志记录:在文档被实际写入到内存或磁盘之前,Elasticsearch会先将其操作记录在事务日志(Translog)中,这是为了确保数据的持久性。
- 刷新(Refresh):Elasticsearch有一个可配置的刷新周期(默认为1秒),在这个周期内,内存中的文档会被刷新到一个新的Lucene段中,并打开供搜索。这意味着文档在被索引后很快(几乎是实时的)就能被搜索到,但这个过程比直接写入硬盘更快,因为段还在内存中。
- 副本同步:一旦文档被成功写入主分片,协调节点还会确保副本分片也得到更新,以维持索引的高可用性。这个过程是异步的,可以配置副本数量来增强数据冗余。
- 确认响应:一旦主分片和所有副本分片(根据配置的副本确认级别)都确认了写入操作,协调节点会向客户端发送一个成功的响应,表明文档已被成功索引。
- 段合并:在后台,Elasticsearch会定期进行段合并,将小的段合并成更大的段,以优化存储和查询性能。这个过程发生在索引和搜索操作之外,不会影响正常的读写操作。
搜索流程
在Elasticsearch (ES) 集群中执行一次搜索请求的大致过程如下:
请求接收:
- 客户端发送搜索请求到Elasticsearch集群中的任意一个节点,这个节点称为**协调节点(coordinating node)**。
解析与路由:
- 协调节点解析搜索请求,包括查询条件、过滤器、排序方式等,并根据索引信息确定哪些分片可能包含相关数据。在ES中,数据被分割成多个分片(shards),每个分片可以有零个或多个副本(replicas)。协调节点会根据分片信息决定需要向哪些分片发起搜索请求。
查询转发:
- 协调节点将搜索请求转发给持有相关数据分片的节点。这一步骤会根据网络往返次数最小化或非最小化策略进行。如果是最小化策略,协调节点尝试减少与各个分片的交互次数,可能一次性向多个节点发送请求;非最小化策略则可能涉及更多次的交互。
分片级别搜索:
- 每个持有相关分片的节点在其本地分片上执行搜索操作,生成该分片上的匹配结果集。这一步可能包括倒排索引的查询、文档评分、排序等操作。
结果汇总:
- 各个分片节点将搜索结果返回给协调节点。协调节点对这些结果进行汇总处理,可能包括去重、合并、排序以及根据请求参数执行后续的聚合操作。
结果剪裁与排序:
- 协调节点根据请求中的分页参数、排序规则等对汇总的结果进行剪裁和排序,以准备最终返回给客户端的数据集。
响应构建与返回:
- 协调节点将最终的搜索结果封装成响应体,并通过HTTP响应的形式返回给客户端。
整个过程中,Elasticsearch利用其分布式特性并行处理请求,提高了搜索效率。此外,Elasticsearch还提供了丰富的API和机制来优化搜索性能,如预处理节点(ingest node)可以对数据进行预处理,而复制机制确保了数据的高可用性。
参考资料
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 duval1024@gmail.com

